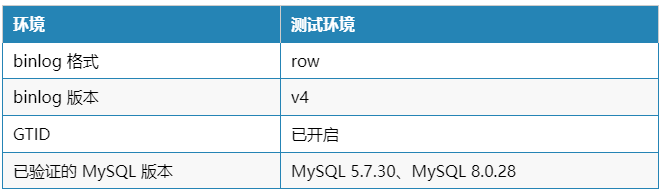
1、序
大事务想必大家都遇到过,既然要对大事务进行拆分,第一步就是要找到它。那么如何通过binlog来定位到大事务呢?
首先,可通过binlog文件的大小来判断是否存在大事务,当一个binlog文件快被写完时,突然出现大事务,会突破 max_binlog_size 的大小继续写入。
官方文档中是这样描述的:
A transaction is written in one chunk to the binary log, so it is never split between several binary logs. Therefore, if you have big transactions, you might see binary log files larger than max_binlog_size.
根据这个特点,只要进入 binlog 的存放目录,观察到文件大小异常的 binlog,那么你就可以去解析这个 binlog 获取大事务了。
当然,需要注意的是,这只是一部分,文件大小正常的 binlog 中也藏着大事务。
2、实践
既然要定位大事务的SQL,针对已开启 GTID 的实例,只要定位到对应的GTID即可,下面我们开始对一个binlog进行解析:
![图片[1]-如何通过binlog定位大事务?-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/03/image-107.png?imageMogr2/format/webp/interlace/1/quality/100)
首先,我们解析出一个binlog中按照事务大小排名前 N 的事务。
# 为了方便保存为脚本,这里定义几个基本的变量
BINLOG_FILE_NAME=$1 # binlog文件名
TRANS_NUM=$2 # 想要获取的事务数量
MYSQL_BIN_DIR='/data/mysql/3306/base/bin' # basedir
# 获取前TRANS_NUM个大事务
${MYSQL_BIN_DIR}/mysqlbinlog ${BINLOG_FILE_NAME} | grep "GTID$(printf '\t')last_committed" -B 1 | grep -E '^# at' | awk '{print $3}' | awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp,tmp);tmp=$1}' | sort -n -r -k 1 | head -n ${TRANS_NUM} > binlog_init.tmp经过第一步对 binlog 的基本解析后,我们已经拿到了对应事务的大小和可供定位 GTID 的 POS 信息,接下来对上述输出的临时文件进行逐行解析,针对每一个事务获取到相应的信息。
while read line
do
# 事务大小这里取近似值,因为不是通过(TRANS_END_POS-TRANS_START_POS)计算出的
TRANS_SIZE=$(echo ${line} | awk '{print $1}')
logWriteWarning "TRANS_SIZE: $(echo | awk -v TRANS_SIZE=${TRANS_SIZE} '{ print (TRANS_SIZE/1024/1024) }')MB"
FLAG_POS=$(echo ${line} | awk '{print $2}')
# 获取GTID
${MYSQL_BIN_DIR}/mysqlbinlog -vvv --base64-output=decode-rows ${BINLOG_FILE_NAME} | grep -m 1 -A3 -Ei "^# at ${FLAG_POS}" > binlog_parse.tmp
GTID=$(cat binlog_parse.tmp | grep -i 'SESSION.GTID_NEXT' | awk -F "'" '{print $2}')
# 通过GTID解析出事务的详细信息
${MYSQL_BIN_DIR}/mysqlbinlog --base64-output=decode-rows -vvv --include-gtids="${GTID}" ${BINLOG_FILE_NAME} > binlog_gtid.tmp
START_TIME=$(grep -Ei '^BEGIN' -m 1 -A 3 binlog_gtid.tmp | grep -i 'server id' | awk '{print $1,$2}' | sed 's/#//g')
END_TIME=$(grep -Ei '^COMMIT' -m 1 -B 1 binlog_gtid.tmp | head -1 | awk '{print $1,$2}' | sed 's/#//g')
TRANS_START_POS=$(grep -Ei 'SESSION.GTID_NEXT' -m 1 -A 1 binlog_gtid.tmp | tail -1 | awk '{print $3}')
TRANS_END_POS=$(grep -Ei '^COMMIT' -m 1 -B 1 binlog_gtid.tmp | head -1 | awk '{print $7}')
# 输出
logWrite "GTID: ${GTID}"
logWrite "START_TIME: $(date -d "${START_TIME}" '+%F %T')"
logWrite "END_TIME: $(date -d "${END_TIME}" '+%F %T')"
logWrite "TRANS_START_POS: ${TRANS_START_POS}"
logWrite "TRANS_END_POS: ${TRANS_END_POS}"
# 统计对应的DML语句数量
logWrite "该事务的DML语句及相关表统计:"
grep -Ei '^### insert' binlog_gtid.tmp | sort | uniq -c
grep -Ei '^### delete' binlog_gtid.tmp | sort | uniq -c
grep -Ei '^### update' binlog_gtid.tmp | sort | uniq -c
done < binlog_init.tmp至此,我们已经基本实现了通过解析一个 binlog 文件,从而拿到对应的 GTID、事务开始和结束时间、事务开始和结束的 POS、对应的 DML 语句数量统计。
为了不重复执行解析命令,我们可以将其封装为脚本,作为日常运维工具使用。
最终效果展示
[root@localhost ~]$ sh parse_binlog.sh /opt/sandboxes/rsandbox_5_7_35/master/data/mysql-bin.000003 2
2023-12-12 15:15:40 [WARNING] 开始解析BINLOG: /opt/sandboxes/rsandbox_5_7_35/master/data/mysql-bin.000003
2023-12-12 15:15:53 [WARNING] TRANS_SIZE: 0.00161743MB
2023-12-12 15:16:06 [INFO] GTID: 00020236-1111-1111-1111-111111111111:362779
2023-12-12 15:16:06 [INFO] START_TIME: 2023-12-12 15:14:35
2023-12-12 15:16:06 [INFO] END_TIME: 2023-12-12 15:14:35
2023-12-12 15:16:06 [INFO] TRANS_START_POS: 362096066
2023-12-12 15:16:06 [INFO] TRANS_END_POS: 362097697
2023-12-12 15:16:06 [INFO] 该事务的DML语句及相关表统计:
1 ### INSERT INTO `sbtest`.`sbtest100`
1 ### DELETE FROM `sbtest`.`sbtest100`
2 ### UPDATE `sbtest`.`sbtest100`
2023-12-12 15:16:06 [WARNING] TRANS_SIZE: 0.00161648MB
2023-12-12 15:16:25 [INFO] GTID: 00020236-1111-1111-1111-111111111111:505503
2023-12-12 15:16:25 [INFO] START_TIME: 2023-12-12 15:15:36
2023-12-12 15:16:25 [INFO] END_TIME: 2023-12-12 15:15:36
2023-12-12 15:16:25 [INFO] TRANS_START_POS: 603539112
2023-12-12 15:16:25 [INFO] TRANS_END_POS: 603540742
2023-12-12 15:16:25 [INFO] 该事务的DML语句及相关表统计:
1 ### INSERT INTO `sbtest`.`sbtest100`
1 ### DELETE FROM `sbtest`.`sbtest100`
1 ### UPDATE `sbtest`.`sbtest100`
1 ### UPDATE `sbtest`.`sbtest87`通过上述结果可以看到,这种解析方式是基于事务的大小进行排序的,有时我们还可能需要从时间维度进行排序,通过大致相同的思路写脚本也可以实现,这里提供一个开源的工具 my2sql。
my2sql可指定 rows 和 time 进行过滤,在 mode 为 file 且 work-type 为 stats 时,连接任意一个 MySQL 实例(无需原库)均可对 binlog 中的事务进行解析。
# 统计指定 binlog 中各个表的 DML 操作数量(不加 row 和 time 限制)
[root@localhost ~]$ mkdir tmpdir
[root@localhost ~]$ ./my2sql -user root -password xxx -host 127.0.0.1 -port 3306 -mode file -local-binlog-file ./mysql-bin.005375 -work-type stats -start-file mysql-bin.005375 -output-dir ./tmpdir
# 按照事务的行数倒序排序
[root@localhost ~]$ less tmpdir/biglong_trx.txt | sort -nr -k 6 | less
# 按照事务的执行时间倒序排序
[root@localhost ~]$ less tmpdir/biglong_trx.txt | sort -nr -k 7 | less
# 输出示例(binlog starttime stoptime startpos stoppos rows duration tables)
mysql-bin.005375 2023-12-12_16:04:06 2023-12-12_16:16:59 493014756 582840954 123336 53 [test.t1(inserts=61668, updates=0, deletes=0) test.t2(inserts=61668, updates=0, deletes=0)]













暂无评论内容