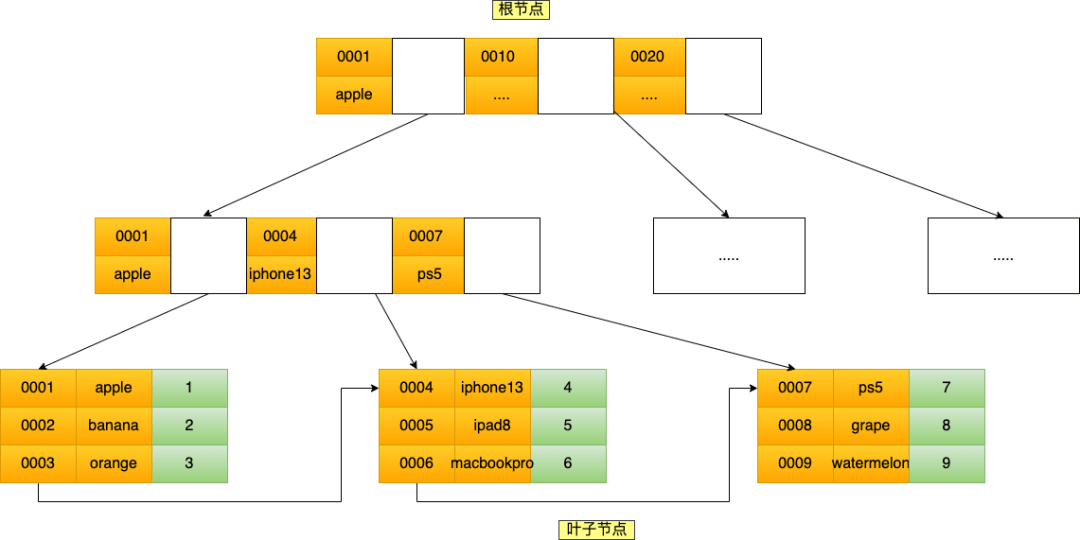
比如,将商品表中的 product_no 和 name 字段组合成联合索引(product_no, name),创建联合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);联合索引(product_no, name) 的 B+Tree 示意图如下(图中叶子节点之间我画了单向链表,但是实际上是双向链表,原图我找不到了,修改不了,偷个懒我不重画了,大家脑补成双向链表就行)。
![图片[1]-什么是联合索引-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/03/image-88.png?imageMogr2/format/webp/interlace/1/quality/100)
可以看到,联合索引的非叶子节点用两个字段的值作为 B+Tree 的 key 值。
当在联合索引查询数据时,先按 product_no 字段比较,在product_no相同的情况下再按 name 字段比较。
也就是说,联合索引查询的 B+Tree 是先按 product_no 进行排序,然后再product_no相同的情况再按name字段排序。
因此,使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。
在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就无法利用到索引快速查询的特性了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END
















暂无评论内容