根据 explain 的结果来看,MySQL 可以分为索引排序和 filesort。
索引排序
如果查询中的 ORDER BY 子句包含的字段已经在索引中,并且索引的排列顺序和 ORDER BY 子句一致,则可直接利用索引进行排序。这种方式效率最高,因为索引有序。
filesort
当使用 explain 分析 SQL 发现执行计划的 extra 中包含 using filesort 的时候,说明它无法应用索引的顺序,而主动排序了。
如果需要排序的数据比较少,则直接在内存中通过 sort_buffer 就能排了。具体是通过 sort_buffer_size 参数来控制 sort_buffer 的大小,如果需要排序的数据量小于 sort_buffer 则直接在内存中排序,反之需要利用磁盘临时文件排序,性能就比较差了。
内存排序
在 sort_buffer 中排序有一些细节需要知晓一下。
双路排序
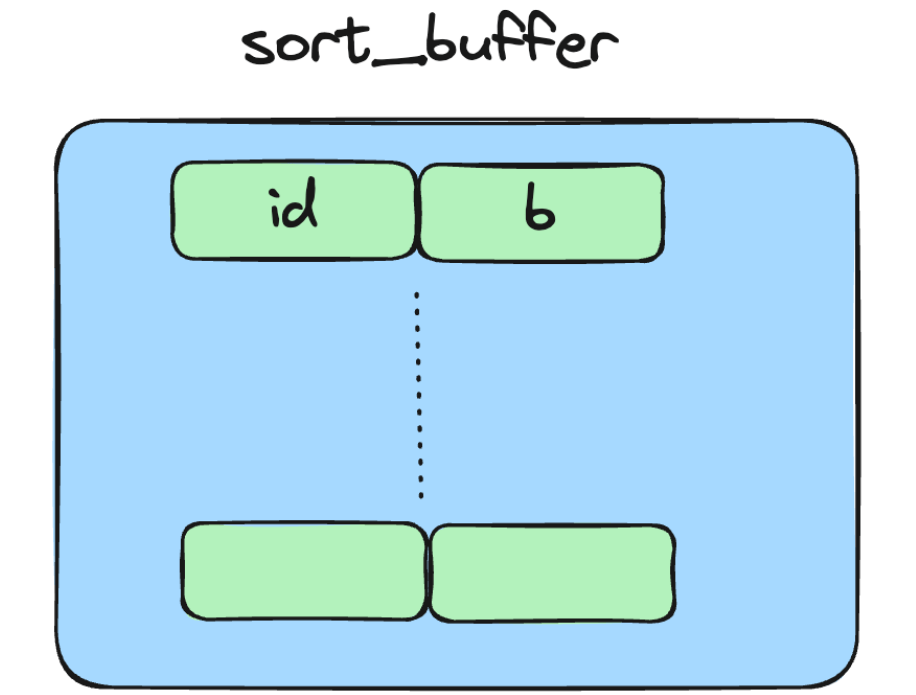
有一个叫 max_length_for_sort_data 参数,默认是 1024 字节,如果 select 列的数据长度超过它,则 MySQL 采用row_id 排序,即把 row_id(有主键就是主键)+排序字段放置到 sort_buffer 中排序。
我们来举例理解下双路排序。
比如现在要执行:
select a,b,c from t1 where a = '编程社' order by b;假设此表单行超过了 max_length_for_sort_data,为了节省排序占用的空间,此时 sort_buffer 只会有放置 id 和 b 来排序。
![图片[1]-MySQL是如何实现数据的排序的?-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/08/image-1.png?imageMogr2/format/webp/interlace/1/quality/100)
排序后,再通过 id 回表查询得到 a、b、c ,最终将最后的结果集返回给客户端。
所以排序需要多个回表的过程,等于需要两次查询,也叫双路排序(Two-Pass Sort)。
单路排序
假设 select 列的数据没有超过 max_length_for_sort_data,则可以进行单路排序(Single-Pass Sort),就是将 select 的字段都放置到 sort_buffer 中。
![图片[2]-MySQL是如何实现数据的排序的?-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/08/image-3.png?imageMogr2/format/webp/interlace/1/quality/100)
排序后直接得到结果集,返回给客户端即可,相比双路排序它减少了回表的动作,因此效率更高。
一开始 MySQL 只有双路排序,后续优化推出了单路排序。
磁盘文件临时排序
前面提到,如果查询的数据超过 sort_buffer,说明内存放不下了,因此需要利用磁盘文件进行外部排序,一般会使用归并排序,简单理解就是将数据分为很多份文件,单独对文件排序,之后再合并成一个有序的大文件。
利用磁盘排序效率会更低,针对一些情况可以调大 sort_buffer_size,避免磁盘临时文件排序。















暂无评论内容