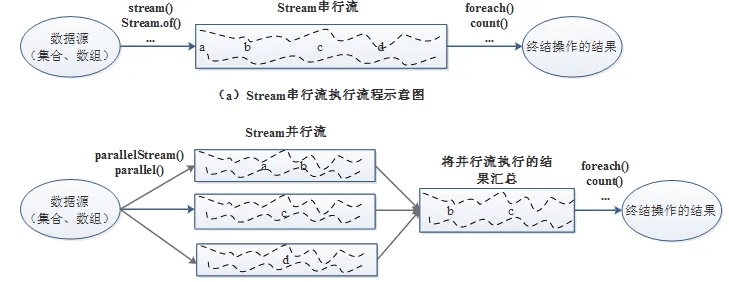
并行流(ParallelStream)就是将源数据分为多个子流对象进行多线程操作,然后将处理的结果再汇总为一个流对象,底层是使用通用的 fork/join 池来实现,即将一个任务拆分成多个“小任务”并行计算,再把多个“小任务”的结果合并成总的计算结果
Stream串行流与并行流的主要区别:
![图片[1]-Stream流的并行API是什么?-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/05/image-99.png?imageMogr2/format/webp/interlace/1/quality/100)
对CPU密集型的任务来说,并行流使用ForkJoinPool线程池,为每个CPU分配一个任务,这是非常有效率的,但是如果任务不是CPU密集的,而是I/O密集的,并且任务数相对线程数比较大,那么直接用ParallelStream并不是很好的选择。
底层使用线程池的核心线程数
ParallelStream 底层使用了 ForkJoinPool 线程池。
ForkJoinPool 与 ThreadPoolExecutor 是完全不同的实现机制。ForkJoinPool 有四个参数可以设置:
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}但其实关键参数也只有一个线程数 parallelism(并行度,默认为CPU数,最小为1),其它参数影响不大。
ForkJoinPool 机制特殊,每个线程都有自己独立的队列,并且没有核心线程和最大线程的概念。
ForkJoinPool 线程数的设置很简单,分 cpu 密集型任务和 io 密集型任务两种情况考虑。
对于cpu密集型任务,建议都用静态的 commonPool(线程数为 CPU 核心数 – 1,JDK 已经设置好了)原因是,如果 new 出多各 ForkJoinPool:
- 浪费内存:ForkJoinPool 内存占用与线程数成正比,而且还挺大,可以计算,一个队列一个 ForkJoinTask 数组,数组初始容量就有 2^13,存储的是 ForkJoinTask 引用,一个对象引用占用 4 字节,那么一个队列占用 2^13 * 4 + 8 Byte 约等于 32 KB,如果设置了 16 线程,那么会有 32 个队列(大于等于线程数的最小 2 的 n 次幂乘 2),也就是 1M,多一个 16 线程的 ForkJoinPool 仅队列自身,一个任务都没有就多占用 1M 内存,再加上拆分出一堆子任务占用内存更多;
- 影响性能:多占用内存,不仅没有性能提升,反而可能有性能损耗,cpu 密集型任务线程数最多也就 cpu 核心数,再多除了增加线程上下文切换次数没什么意义。
对于 io 密集型任务,线程数设置逻辑与 ThreadPoolExecutor 类似,队列容量无限大不可设置,在此基础上寻找合适的线程数即可。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END















暂无评论内容