我们使用 Kafka 的时候,怎样能保证不丢失消息呢?今天来聊一聊这个话题。
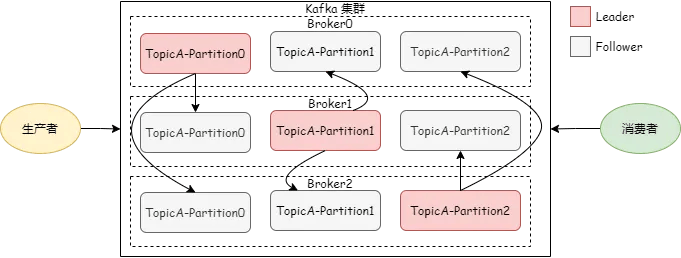
首先我们看一下 Kafka 的架构图
![图片[1]-Kafka丢消息的6种场景-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/04/image.png?imageMogr2/format/webp/interlace/1/quality/100)
场景一:异步发送
Producer 异步发送是丢失消息比较多的场景,Kafka 异步发送的代码如下:
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("the-topic", key, value);
RecordMetadata metadata = producer.send(record).get();Producer 发送消息后,不用等待发送结果,就可以继续执行后面的逻辑。如果发送失败,就会丢失消息。
Kafka 提供了回调方法,可以同步等待发送结果,这样降低了发送效率,但可以对发送失败的场景进行处理,比如重新发送。
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("the-topic", key, value);
producer.send(record,
(Callback) (metadata, e) -> {
if(e != null) {
e.printStackTrace();
} else {
System.out.println("The offset of the record we just sent is: " + metadata.offset());
}
});场景二:配置 acks=0
从文章开头的架构图中可以看到,Broker Leader 节点收到消息后,会同步给 Follower 节点。
在 Producer 端有一个 acks 配置,说明如下 :
- acks=0:Producer 发送消息后不等待 Broker 的响应;
- acks=1:Producer 发送消息后,Leader 节点写入消息成功后给 Producer 发送响应;
- acks=all/-1:Producer 发送消息后,需要 ISR 列表中所有 Broker 节点都写入消息成功才会给 Producer 发送响应。
注意:acks=all/-1 是最高安全级别,可以配合 min.insync.replicas 参数使用,当 acks=all/-1 时,min.insync.replicas 表示 ISR 列表中最小写入消息成功的副本数。
如下图,cks=all/-1,当 min.insync.replicas=2 时,
![图片[2]-Kafka丢消息的6种场景-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/04/image-1.png?imageMogr2/format/webp/interlace/1/quality/100)
如果 ISR 列表中有【Broker0、Broker1】,即使 Broker2 写入消息失败,也会给 Producer 返回成功。
如果 ISR 列表中只有【Broker0】,则无论如何都不会给 Producer 返回成功。
如果 ISR 列表中有【Broker0、Broker1、Broker2】,则 3 个 Broker 都写成功才会给 Producer 返回成功。
场景三:发送端重试
如果配置 retries=0,Producer 发送消息失败后是不会进行重试的,要保证消息不丢失,可以增加 retries 的配置值,避免因为网络抖动而造成的发送失败。
场景四:Follower 落后太多
Kafka Broker 有一个参数:unclean.leader.election.enable,这个参数值说明如下:
- true:允许 ISR 列表之外的节点参与竞选 Leader;
- false:不允许 ISR 列表之外的节点参与竞选 Leader。
如果设置为 true,也是会丢失消息的,看下图:
![图片[3]-Kafka丢消息的6种场景-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/04/image-2.png?imageMogr2/format/webp/interlace/1/quality/100)
如果 Leader 和 Follower1 都挂了,这时就要考虑是否让 Follower2 参加竞选,把 unclean.leader.election.enable 参数值设置为 true,则 Follower2 也可以竞选 Leader,并且作为唯一存活节点成功竞选为 Leader,但是它并没有同步到偏移量为 3、4、5 的消息,
而之前的 Leader 上线后,成为了 Follower,因为 Follower 的 LEO(Log End Offset)不能大于 Leader,所以之前偏移量为 3、4、5 的消息就被丢弃了。如下图:
![图片[4]-Kafka丢消息的6种场景-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/04/image-3.png?imageMogr2/format/webp/interlace/1/quality/100)
所以,要保证消息不丢失,unclean.leader.election.enable 这个参数值要设置为 false。
场景五:Broker 宕机
为了提升性能,Kafka 使用 Page Cache,先将消息写入 Page Cache,采用了异步刷盘机制去把消息保存到磁盘。如果刷盘之前,Broker Leader 节点宕机了,并且没有 Follower 节点可以切换成 Leader,则 Leader 重启后这部分未刷盘的消息就会丢失。
这种场景下多设置副本数是一个好的选择,通常的做法是设置 replication.factor >= 3,这样每个 Partition 就会有 3 个以上 Broker 副本来保存消息,同时宕机的概率很低。
同时可以配合场景二中的参数 min.insync.replicas > 1(不建议使用默认值 1),表示消息至少要被成功写入到 2 个 Broker 副本才算是发送成功。
注意:参数配置要保证 replication.factor > min.insync.replicas,通常设置成 replication.factor = min.insync.replicas + 1。如果这 2 个参数设置成相等,则只要有一个 Broker 节点宕机,Broker 就无法给 Producer 返回发送成功,系统可用性降低。
场景六:并发消费
如果消费端采用多线程并发消费,很容易因为并发更新 Offset 导致消费失败。
看下图:
![图片[5]-Kafka丢消息的6种场景-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/04/image-4.png?imageMogr2/format/webp/interlace/1/quality/100)
线程 1 拉取 3 条消息把 Offset 更新成 3,线程 2 把 Offset 更新成 6,线程 3 把 Offset 更新成 9。这时如果线程 2 消费失败了,想要重新消费,但是 Offset 已经更新到了 9,不能拉取到 Offset 9 以前的消息了。
所以,消费者并发消费很可能会造成消息丢失,如果对消息丢失很敏感,最好使用单线程来进行消费。
如果采用多线程,可以把 enable.auto.commit 设置为 false,这样相当于每次消费完后手动更新 Offset。
不过这又会带来重复消费问题,比如上面的例子,如果线程 2 消费失败了,则手动把 Offset 更新成 3,线程 3 消费成功后,再次拉取,还会拉取到 6、7、8 这三条数据。
因此消费端需要做好幂等处理。














暂无评论内容