Redis是一款强大的内存数据存储,被广泛用于缓存、会话管理、实时分析等场景。
Redis有一个关键特性就是其对逻辑数据库的支持,可以使用户在单个Redis实例中对数据进行分区。
这些逻辑数据库提供了隔离和在键方面的不同命名空间,从而实现更有效的数据管理和组织。
在本篇文章中,不念将展示如何利用逻辑数据库来提升Redis查询性能。
逻辑数据库
Redis支持多个逻辑数据库,通常称为“数据库编号”或“DB”。
每个逻辑数据库都是相互隔离的,一个数据库中存储的数据是无法直接从另一个数据库中访问。
这种隔离提供了一种对数据进行逻辑分区的方式。
在Redis中,键在数据库内是唯一的。
因此,不同的数据库为键提供了独立的命名空间,允许在不发生冲突的情况下在不同的数据库中使用相同的键。
![图片[1]-如何优化Redis扫描性能-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/03/image-139.png?imageMogr2/format/webp/interlace/1/quality/100)
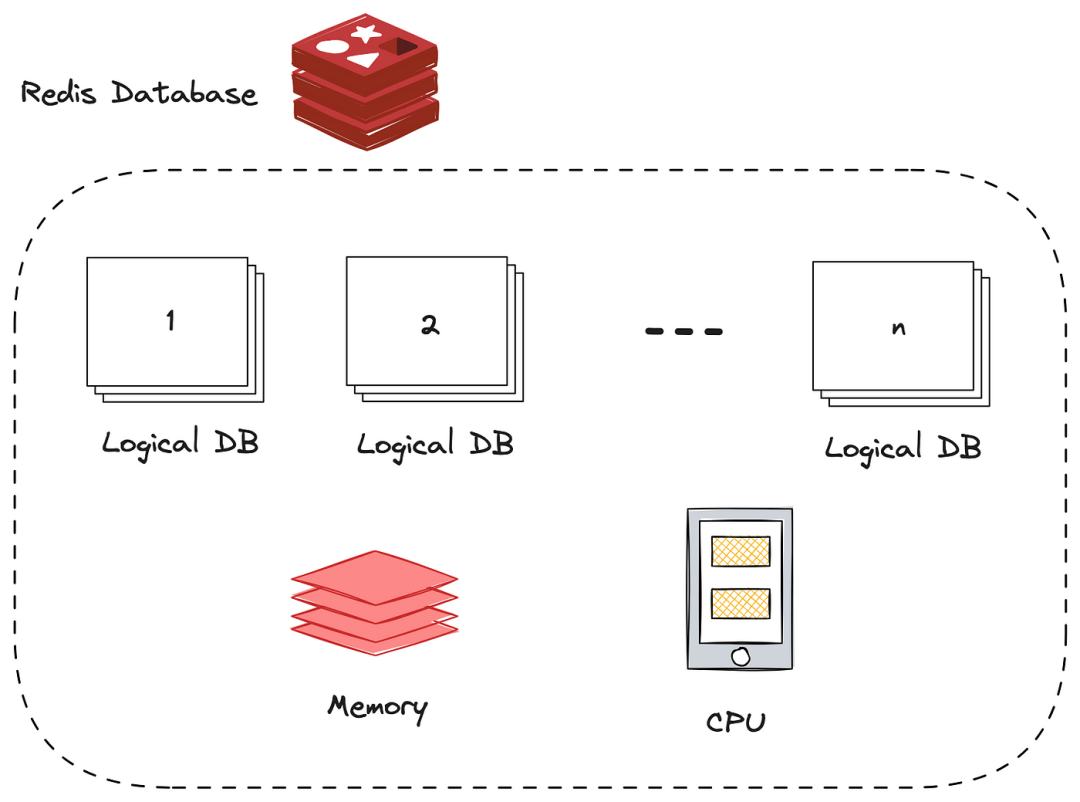
带有逻辑数据库和共享资源(CPU 和内存)的 Redis 实例
虽然逻辑数据库提供了隔离,但它们仍然在单个Redis实例内共享相同的底层物理资源(内存、CPU 等)。
因此,对一个数据库的大量使用可能潜在地影响其他数据库的性能。
扫描性能
尽管Redis不是专为像传统关系型数据库那样的复杂查询而设计的,但在某些情况下,您可能需要获取具有相同前缀的一组键。这是一个常见的需求,特别是在键按层次结构组织或按公共标识符分组的场景中。
让我们深入探讨一个性能查询取决于数据库大小的场景。假设您正在使用 Redis 缓存最近访问您网站的用户的值,TTL(生存时间)为 24 小时。这些缓存的值存储在前缀为 user_id 下。此外,您还有一个用于当前正在使用您服务的用户的 Active Users 缓存,前缀为 active_user_id,TTL 为 2 小时。现在,您有一个定期检查有多少活跃用户并使用 Active Users 缓存的过程。以下是性能如何受数据库大小影响的一个示例。
随着越来越多的用户访问您的网站并将其数据缓存在 Redis 中,前缀为 user_id 的数据库大小将增长。令人惊讶的是,即使活跃用户数量稳定,扫描活跃用户的速度也可能变慢。
这是因为 SCAN 命令遍历数据库中的所有键,并之后应用前缀模式。请参阅以下实现。我们有一个简单的函数,用于使用给定前缀向 Redis 数据库填充随机记录。
import random
import redis
import string
def populate_db(host, port, db_number, key_prefix, n):
r = redis.Redis(host=host, port=port, db=db_number)
# 生成并将随机数据加载到 Redis
for i in range(n):
suffix = ''.join(random.choices(string.ascii_letters, k=5))
key = f"{key_prefix}{suffix}"
value = ''.join(
random.choices(string.ascii_letters + string.digits, k=5),
)
r.set(key, value)
print("数据加载到 Redis。")在 Redis 中,SCAN 命令用于安全而高效地遍历数据库中的键。
使用基于游标的迭代方法与 SCAN 而不是一次性获取所有键(KEYS <prefix>)的主要原因是确保该操作不会阻塞 Redis服务器或在数据库较大的情况下对其性能产生负面影响。
import redis
import time
def scan_redis_by_pattern(host, port, db_number, pattern):
r = redis.Redis(host=host, port=port, db=db_number)
num_keys = r.dbsize()
print(f"DB={db_number} 的键数量: {num_keys}")
cursor = 0
keys = []
while True:
cursor, partial_keys = r.scan(cursor, match=pattern)
keys.extend(partial_keys)
if cursor == 0:
break
return keys现在我们根据数据库中的 user_id 记录数量检查 active_user_id 查询性能。
host = 'localhost'
port = 6379
pattern = 'active_user_id:*'
db_number = 0
# populate_db(host, port, db_number, "active_user_id:", 1)
for n in [10, 1000, 10000]:
populate_db(host, port, db_number, "user_id:", n)
start = time.time()
keys = scan_redis_by_pattern(host, port, db_number, pattern)
print(
f"Keys: {keys}, Duration: {time.time() - start}s",
)我们得到以下结果:
数据加载到 Redis。
DB=0 的键数量: 11
Keys: [b'active_user_id:aTtsr'], Duration: 0.004511117935180664s
数据加载到 Redis。
DB=0 的键数量: 1011
Keys: [b'active_user_id:aTtsr'], Duration: 0.051651954650878906s
数据加载到 Redis。
DB=0 的键数量: 100999
Keys: [b'active_user_id:aTtsr
'], Duration: 4.748287916183472s随着数据库中 user_id 键的数量增加,执行 active_user_id 查询所需的时间也会成比例增加(从几毫秒到几秒)。这突显了在设计和管理 Redis 数据库时考虑数据库大小和性能影响的重要性。
如果将 active_user_id 和 user_id 记录保持在不同的逻辑数据库中,那么 user_id 键的数量增加将不会影响 active_user_id 扫描。
数据加载到 Redis。
DB=0 的键数量: 1000990
DB=1 的键数量: 1
Keys: [b'active_user_id:DsHfN'], Duration: 0.003325939178466797s正如我们所见,将数据分隔到逻辑数据库中是一种简单而有效的设计策略,可用于提升Redis性能。
结论
Redis的逻辑数据库为在单个 Redis 实例中组织和管理数据提供了强大的机制。
通过将数据划分到独立的逻辑数据库中,用户可以实现更好的隔离和更高效的数据访问。
然而,必须注意共享内存和 CPU 利用率的潜在性能影响。













暂无评论内容