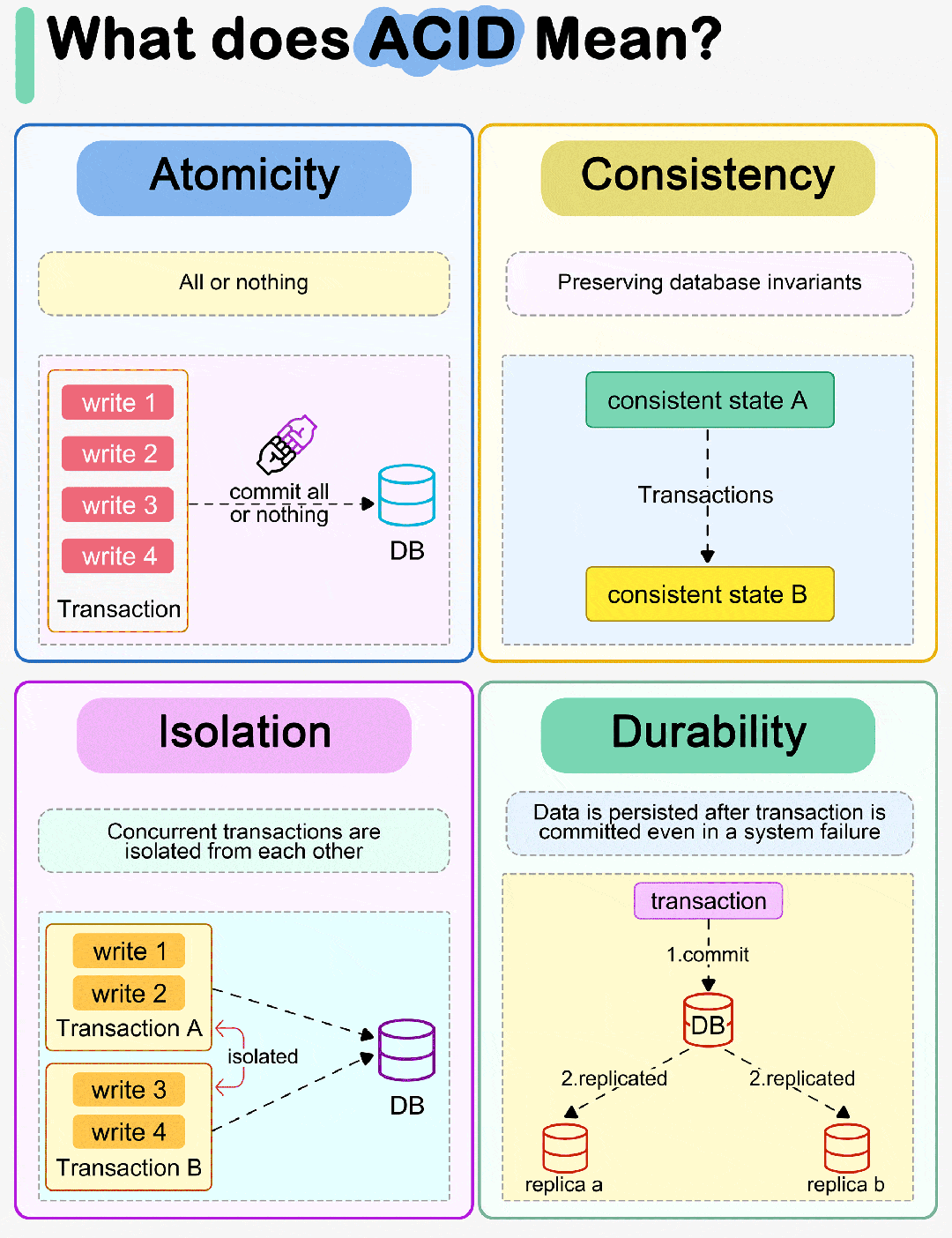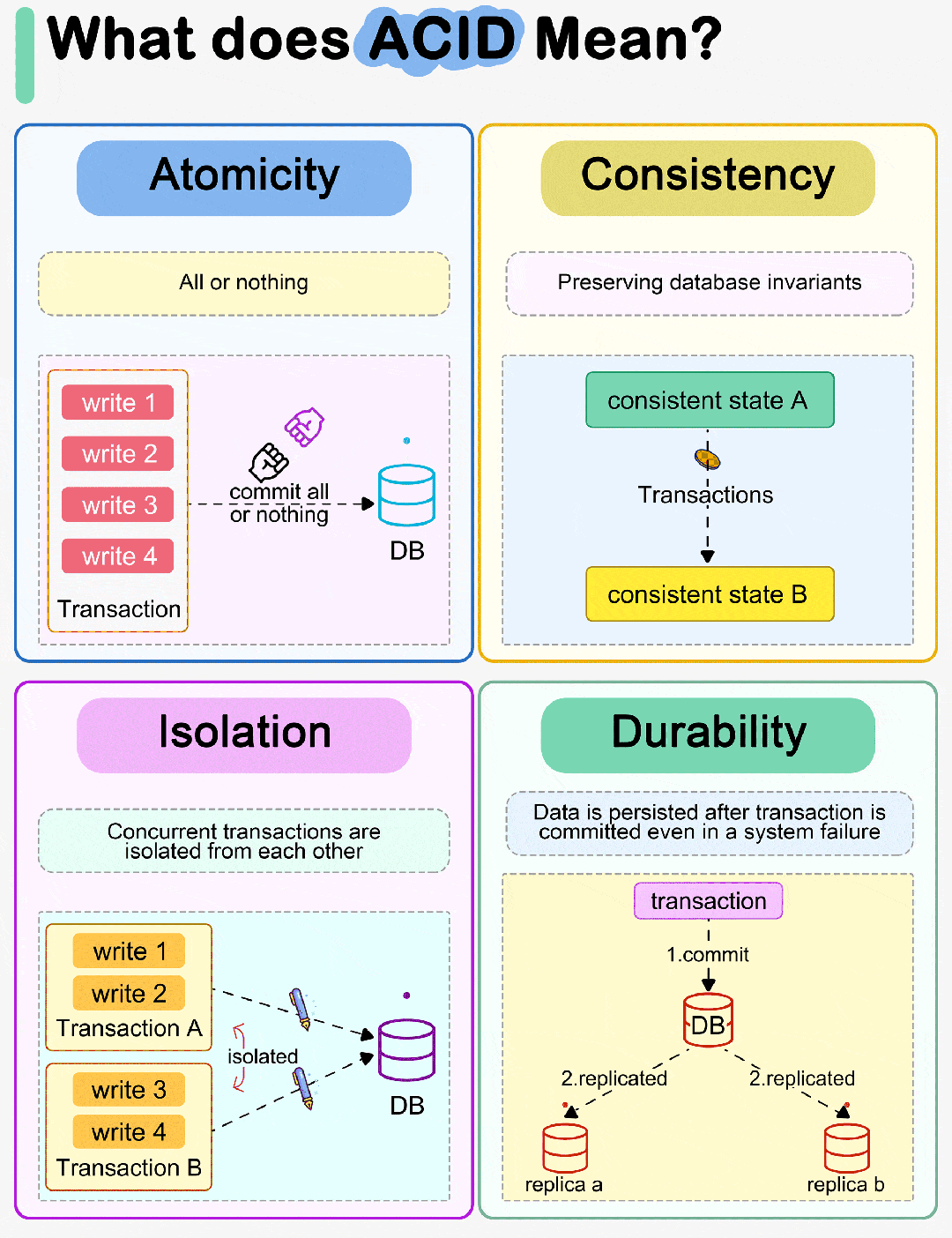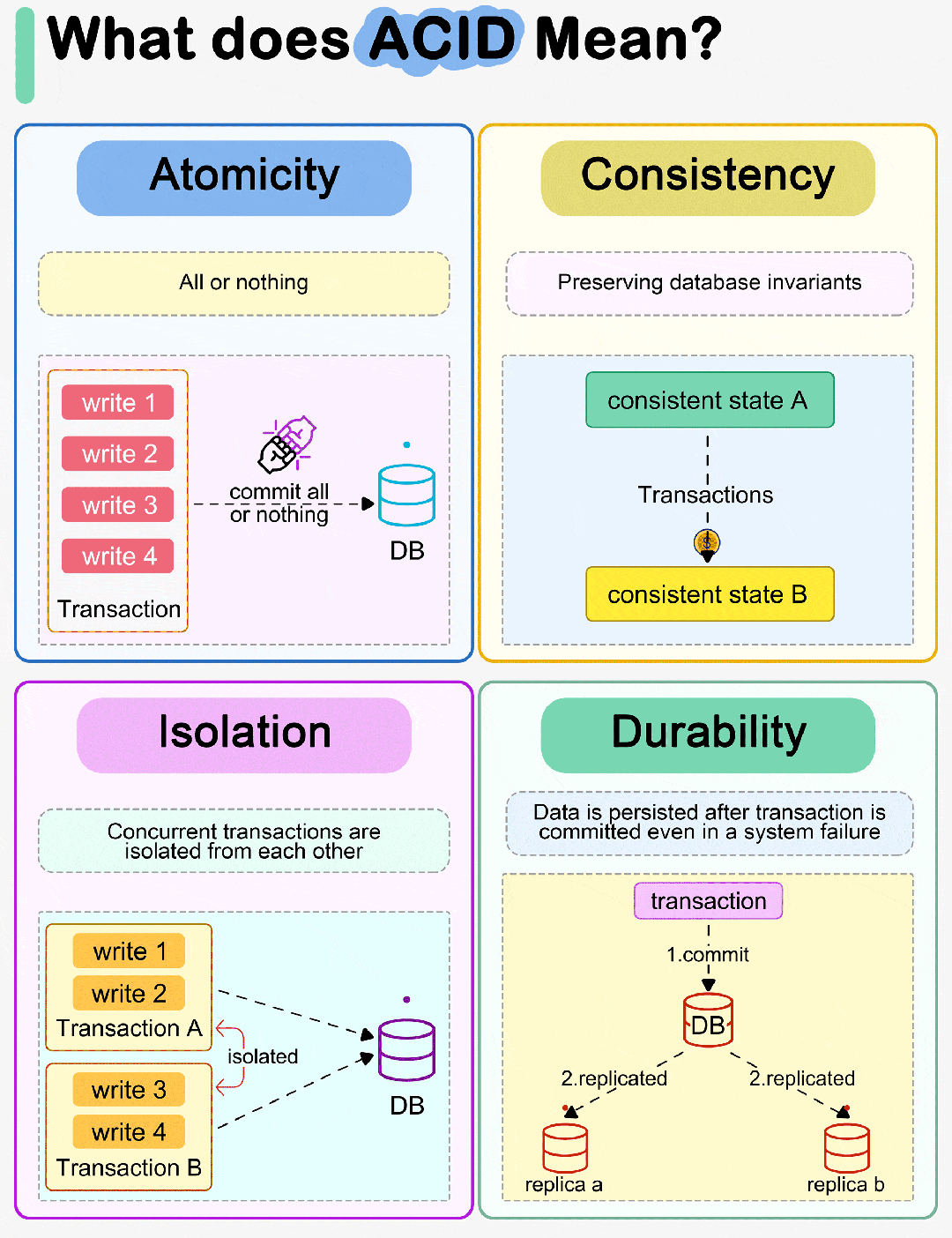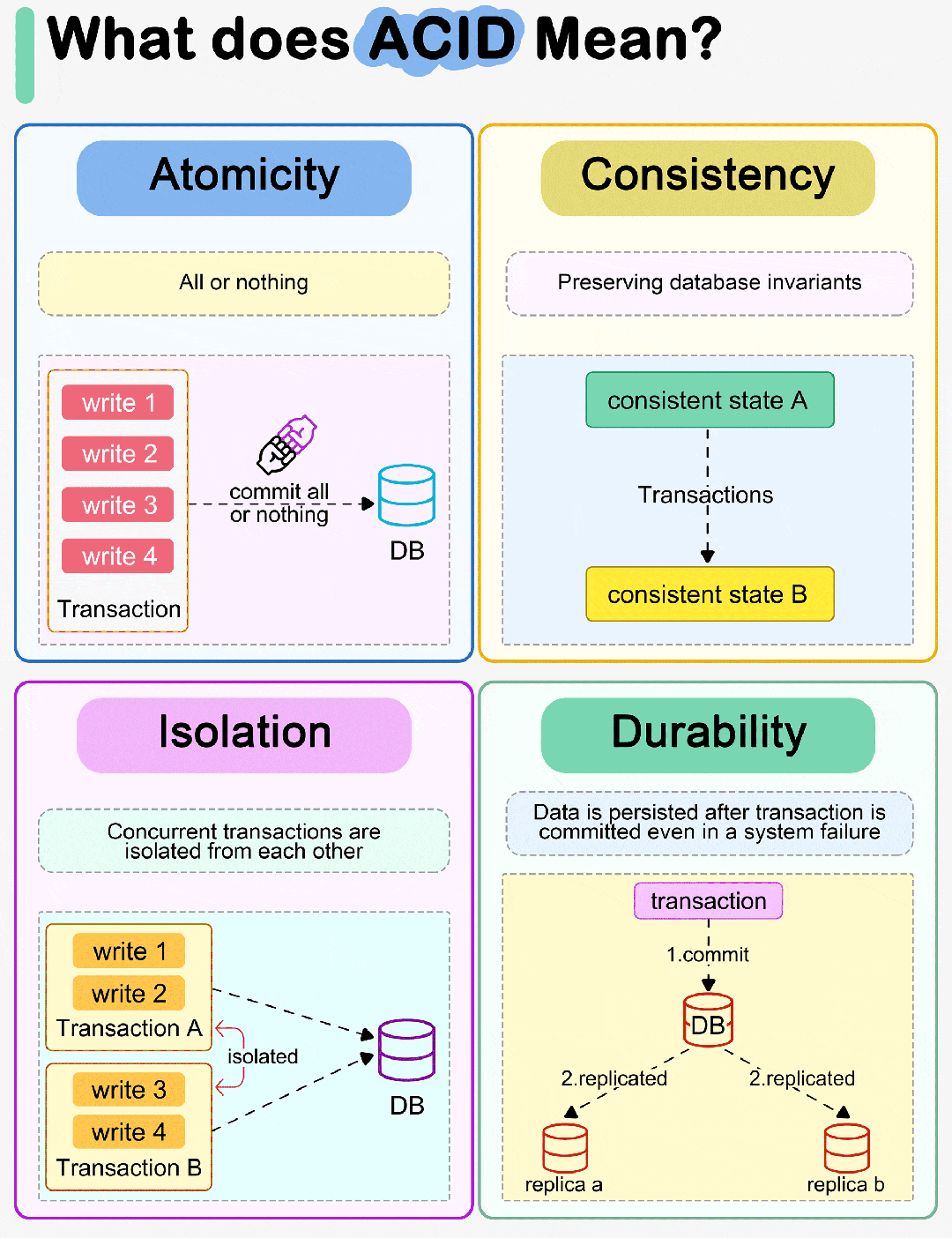
在实际开发种,高性能服务有一条尽量减少系统调用的原则。
对于一个文件描述符(file descriptor,fd,例如文件指针、套接字类型)的 read 或者 write,都是系统调用。
有时候我们会遇到通过一个文件描述对应的文件或套接字上将数据读到多个缓冲区中去,或者将多个缓冲区中的数据同时写入一个文件描述符对应的文件或者套接字中。
![图片[1]-readv和writev函数详解-编程社](https://cos.bianchengshe.com/wp-content/uploads/2024/01/1704695795-image.png?imageMogr2/format/webp/interlace/1/quality/100)
当然,你可以通过多次调用 read 或者 write,挨个操作每个缓冲区。
Linux系统提供了一组readv和writev系列函数来完成上述工作。
这个系列函数的签名如下:
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
ssize_t preadv(int fd, const struct iovec *iov, int iovcnt, off_t offset);
ssize_t pwritev(int fd, const struct iovec *iov, int iovcnt, off_t offset);参数 fd 和 offset 的含义都是不言自明的。
参数 iov 是一个 struct iovec 数组,参数 iovcnt 是该数组元素的个数。
函数 readv 和 preadv 调用成功返回总读取字节数,函数 writev 和 pwritev 调用成功返回总写入字节数,函数调用失败均返回 -1。
struct iovec 定义如下:
struct iovec {
void *iov_base; /* Starting address */
size_t iov_len; /* Number of bytes to transfer */
};字段 iov_base 是存放数据缓冲区的地址,字段 iov_len 是缓冲区的长度。
我们以 writev 函数为例来演示其用法,假设现在我们需要将 3 段数据同时写入一个 CSV 文件中,第一段数据是 CSV 的文件头信息,第二段和第三段是两只股票信息。
示例代码如下:
char* headerInfo = "timestamp,symbol,side,volume,price\n";
char* firstSymbolInfo = "2014-12-12D06:53:11.127838000,600358,Buy,347,3.48\n";
char* secondSymbolInfo = "2014-12-12D06:53:11.127838000,600359,Buy,251,4.99\n";
struct iovec iov[3];
iov[0].iov_base = headerInfo;
iov[0].iov_len = strlen(headerInfo);
iov[1].iov_base = firstSymbolInfo;
iov[1].iov_len = strlen(firstSymbolInfo);
iov[2].iov_base = secondSymbolInfo;
iov[2].iov_len = strlen(secondSymbolInfo);
//fpCSV 为打开的CSV文件句柄
ssize_t nwritten = writev(fpCSV, iov, 2);为了提高程序执行效率,读者可能会在很多 C/C++ 网络库中见到 readv 和 writev 函数的身影。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END











![[网络工程师]-网络规划与设计-通信规范分析-编程社](https://cos.bianchengshe.com/wp-content/uploads/2023/03/image-13.png)



暂无评论内容